
When I was at the GKE summit back in December I talked to one of the PMs about running stateful workloads. While their take was that GKE is mature enough for anyone to run stateful workloads and they’d proudly mentioned that there are thousands of customers out there running MySQL or PostgreSQL on GKE, they were a bit unsure if there were many - or any - customers running a decently sized SQL Server workload on GKE on Linux clusters.
So that got me intrigued. Is it even possible? Spoiler alert - of course it is!
The challenging part about running SQL Server on K8s, is setting up an Always On Availability Group (AG), which in the event of an outage on the primary replica, would automatically failover to one of the secondary replicas.
As a side-note, there seems to be a commercial 3rd party solution for running SQL Server AG on K8s. Perhaps Microsoft will one day offer support for K8s AGs out of the box as well. They did showcase this capability with SQL Server 2019 preview.
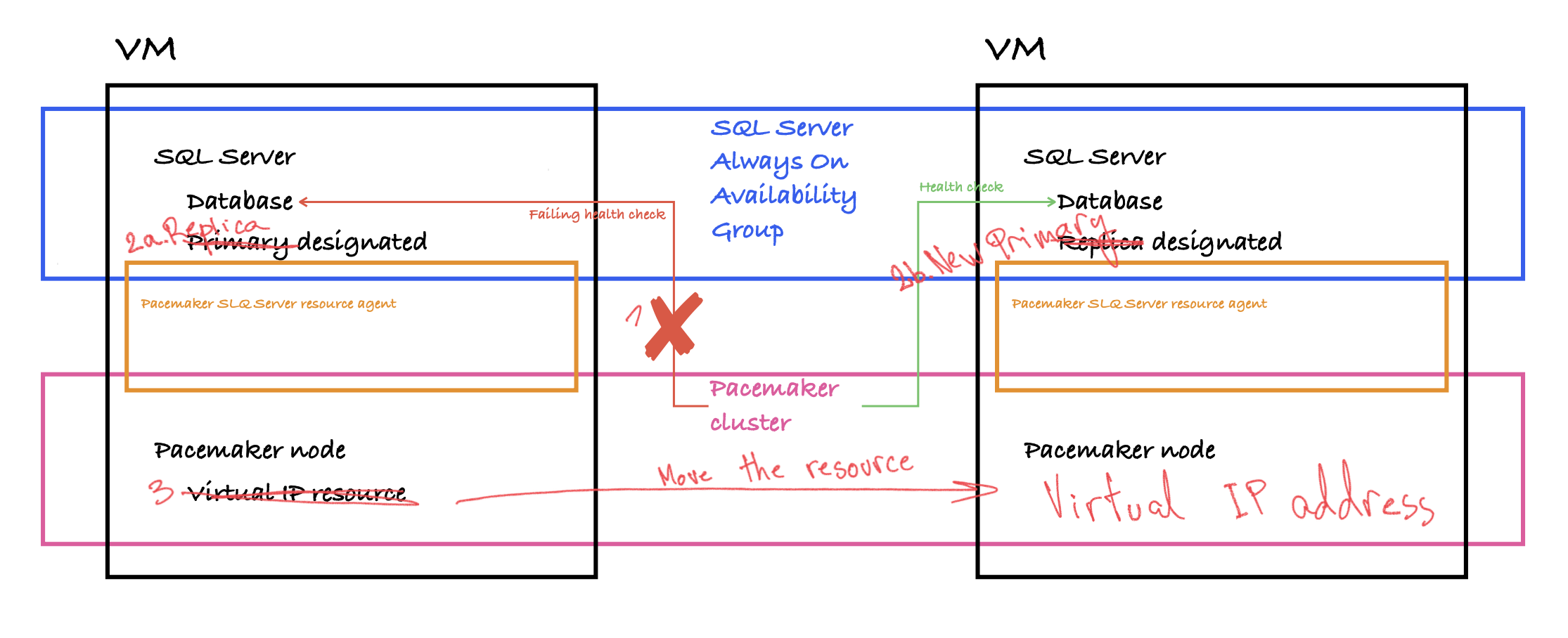
To being with, how does one setup SQL Server AG on Linux? (This is visualized in the image above)
- each SQL Server node runs Pacemaker and the SQL Server resource agent
- Pacemaker runs health checks against the SQL database
- Pacemaker manages the AG
- Pacemaker manages the endpoint on which clients connect, as a virtual IP
In the event of an outage with the primary replica. (This is also visualized in the image above)
- Pacemaker’s health-check towards the SQL database will fail
- Pacemaker will ask SQL AG to trigger a failover and designate a new primary
- Pacemaker will move the Virtual IP resource to the node where the new primary is running
How will this work in K8s?
There are a few networking quirks with running a Pacemaker cluster on a K8s cluster. One relates to how corosync resolves IPs and then caches them throughout the lifetime of the (Pacemaker) cluster. The second, and the main issue I see with the Pacemaker cluster on K8s, is that K8s likes to manage networking, so the concept of a virtual and static IP behind a K8s service is rather problematic.
We could use a K8s service instead.
- Have a K8s service to which all clients connect and which directs traffic to the primary SQL replica
- When an outage occurs and Pacemaker triggers a failover, calls the K8s api to switch the pod behind the K8s service with the, now new, primary SQL replica
In fact, this could be achieved without Pacemaker altogether. We’d need to deploy a service which monitors the health of the primary SQL replica, and when it detects and outage it instructs the SQL AG to trigger a failover. (This is visualized in the image below)
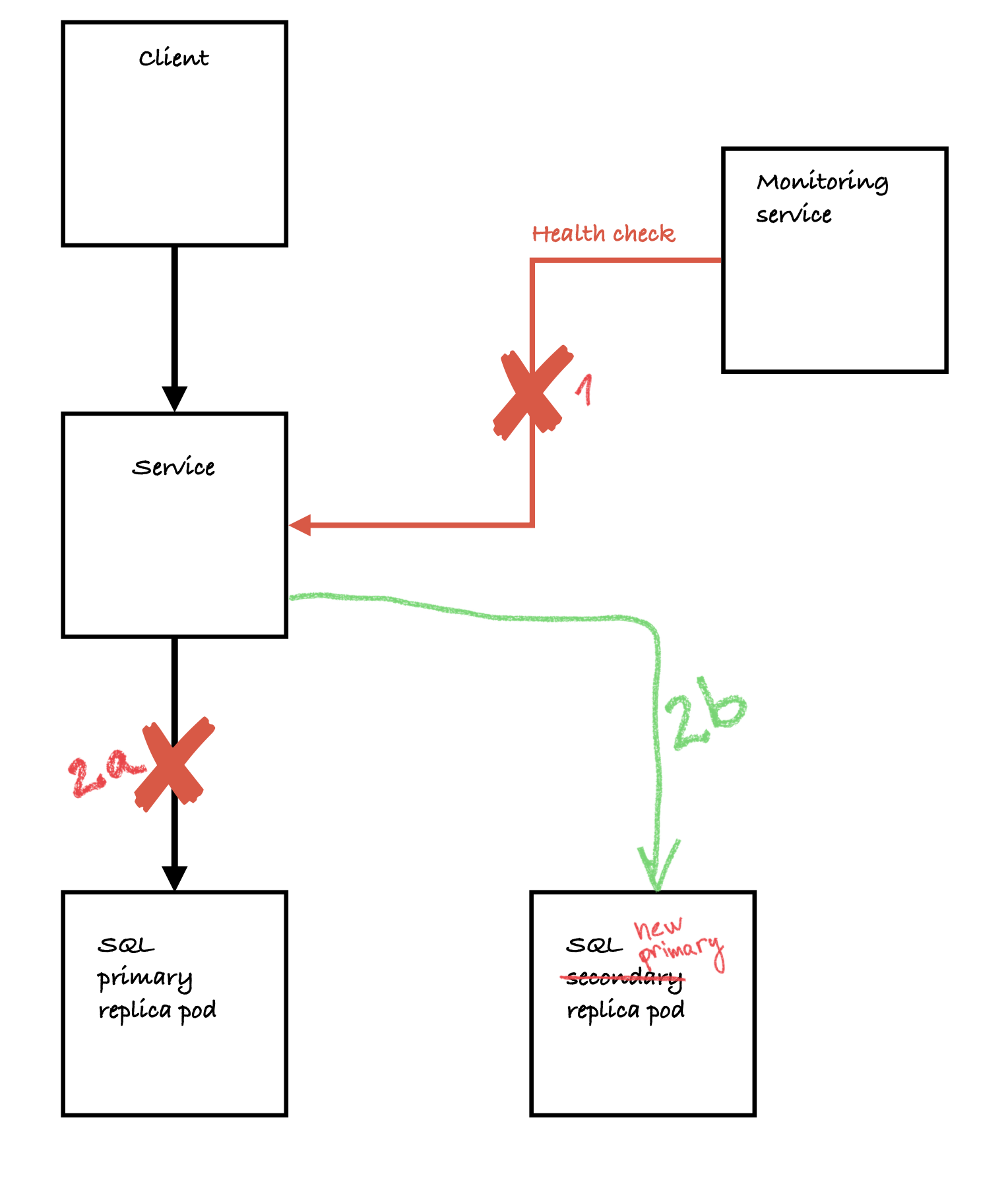
As with everything, it is easier said than done. Will get to do a POC for this, but that’s for another time.
PS. If you’re wondering about the top image, it is the result of asking an AI to generate “a sail ship that is also a datacenter, sailing in the ocean”.